
Wichtige Erkenntnisse
- Multimodale KI verwendet mehrere Eingabequellen (Text, Bilder, Audio, Sensoren), um bessere Ergebnisse und fortschrittlichere Anwendungen zu erzielen.
- Multimodale KI ist kompetenter und kann verschiedene Eingaben verknüpfen, um bessere Ergebnisse zu erzielen.
- Beispiele für multimodale KI-Modelle sind Google Gemini, GPT-4V von OpenAI, Runway Gen-2 und Meta ImageBind.
Frühe KI-Modelle beeindruckten durch ihre Fähigkeit, Texteingaben zu interpretieren, aber multimodale KI kann noch viel mehr. Da bestehende Modelle erweitert werden, um mehr Eingabemodalitäten zu akzeptieren, werden KI-Tools immer fortschrittlicher.
Was bedeutet „multimodal“?
Das Wort „multimodal“ bezieht sich wörtlich auf die Verwendung mehrerer Modi, und im Kontext der KI bedeutet dies die Verwendung verschiedener Eingabequellen sowohl für das Training als auch für fundiertere Ergebnisse. Chatbots, die 2023 die Welt im Sturm eroberten, beherrschten nur einen einzigen Eingabemodus, nämlich Text.

Multimodale KI kann zwei oder mehr Eingabemethoden akzeptieren. Dies gilt sowohl beim Trainieren des Modells als auch bei der Interaktion mit dem Modell. Sie könnten beispielsweise ein Modell trainieren, bestimmte Bilder mit bestimmten Tönen zu verknüpfen, indem Sie sowohl Bild- als auch Audiodatensätze verwenden. Gleichzeitig könnten Sie ein Modell bitten, eine Textbeschreibung und eine Audiodatei zu kombinieren, um ein Bild zu generieren, das beides darstellt.
Mögliche Eingabemodi sind Text, Bilder, Audio oder Informationen von Sensoren wie Temperatur, Druck, Tiefe usw. Diese Modi können innerhalb des Modells priorisiert werden, wobei die Ergebnisse basierend auf dem beabsichtigten Ergebnis gewichtet werden.
Multimodale Modelle sind eine Weiterentwicklung der unimodalen Modelle, die im Jahr 2023 explosionsartig an Popularität gewannen. Unimodale Modelle können nur eine Eingabeaufforderung aus einer einzigen Eingabe (z. B. Text) übernehmen. Ein multimodales Modell kann mehrere Eingaben wie eine Beschreibung, ein Bild und eine Audiodatei kombinieren, um erweiterte Ergebnisse zu liefern.
Inwiefern ist multimodale KI besser als normale KI?
Multimodale KI ist die logische Weiterentwicklung aktueller KI-Modelle, die „wissendere“ Modelle ermöglicht. Die Anwendungsgebiete dieser Modelle sind weitaus vielfältiger, sowohl in Bezug auf die Verwendung durch Verbraucher, maschinelles Lernen als auch branchenspezifische Implementierung.
Angenommen, Sie möchten ein neues Bild auf Grundlage eines Fotos erstellen, das Sie aufgenommen haben. Sie könnten das Foto einer KI zuführen und die gewünschten Änderungen beschreiben. Sie könnten auch ein Modell trainieren, Geräusche mit einem bestimmten Bildtyp zu verknüpfen oder Assoziationen wie Temperatur herzustellen. Diese Arten von Modellen würden „bessere“ Ergebnisse erzielen, selbst wenn Sie nur über Text mit ihnen interagieren.
Weitere Beispiele sind die Untertitelung von Videos mit Audio und Video, um Text mit dem zu synchronisieren, was auf dem Bildschirm passiert, oder die bessere Informationserfassung mithilfe von Diagrammen und Infografiken, um die Ergebnisse zu verbessern. Natürlich sollten Sie bei Gesprächen mit einem Chatbot immer ein gesundes Maß an Skepsis bewahren.
Multimodale KI findet allmählich ihren Weg in die Alltagstechnologie. Mobile Assistenten könnten durch die Verwendung multimodaler Modelle erheblich verbessert werden, da der Assistent über mehr Datenpunkte und zusätzlichen Kontext verfügt, um bessere Annahmen zu treffen. Ihr Smartphone verfügt bereits über Kameras, Mikrofone, Licht- und Tiefensensoren, ein Gyroskop und einen Beschleunigungsmesser, Geolokalisierungsdienste und eine Internetverbindung. All dies könnte für einen Assistenten im richtigen Kontext nützlich sein.
Die Auswirkungen auf die Industrie sind enorm. Stellen Sie sich vor, Sie trainieren ein Modell, um eine Art Wartungsaufgabe mithilfe mehrerer Eingaben auszuführen, damit es bessere Urteile fällen kann. Wird eine Komponente heiß? Sieht die Komponente abgenutzt aus? Ist sie lauter als sie sein sollte? Dies kann mit grundlegenden Informationen wie dem Alter der Komponente und ihrer durchschnittlichen Lebensdauer kombiniert werden. Anschließend können die Eingaben gewichtet werden, um zu vernünftigen Schlussfolgerungen zu gelangen.
Einige Beispiele für multimodale KI
Google Gemini ist vielleicht eines der bekanntesten Beispiele für multimodale KI. Das Modell war nicht unumstritten. Ein Ende 2023 veröffentlichtes Video, das das Modell demonstrierte, wurde von Kritikern als „Fake“ bezeichnet. Google gab zu, dass das Video bearbeitet wurde, dass die Ergebnisse auf Standbildern basierten und nicht in Echtzeit stattfanden und dass die Eingabeaufforderungen per Text und nicht laut gesprochen wurden.


Entwickler können Gemini bereits heute nutzen, indem sie einfach einen API-Schlüssel in Google AI Studio beantragen. Der Dienst wurde auf einer „kostenlosen“ Stufe mit einem Limit von bis zu 60 Abfragen pro Minute gestartet. Sie benötigen gute Python-Kenntnisse, um den Dienst einzurichten (hier finden Sie ein gutes Tutorial für den Einstieg).
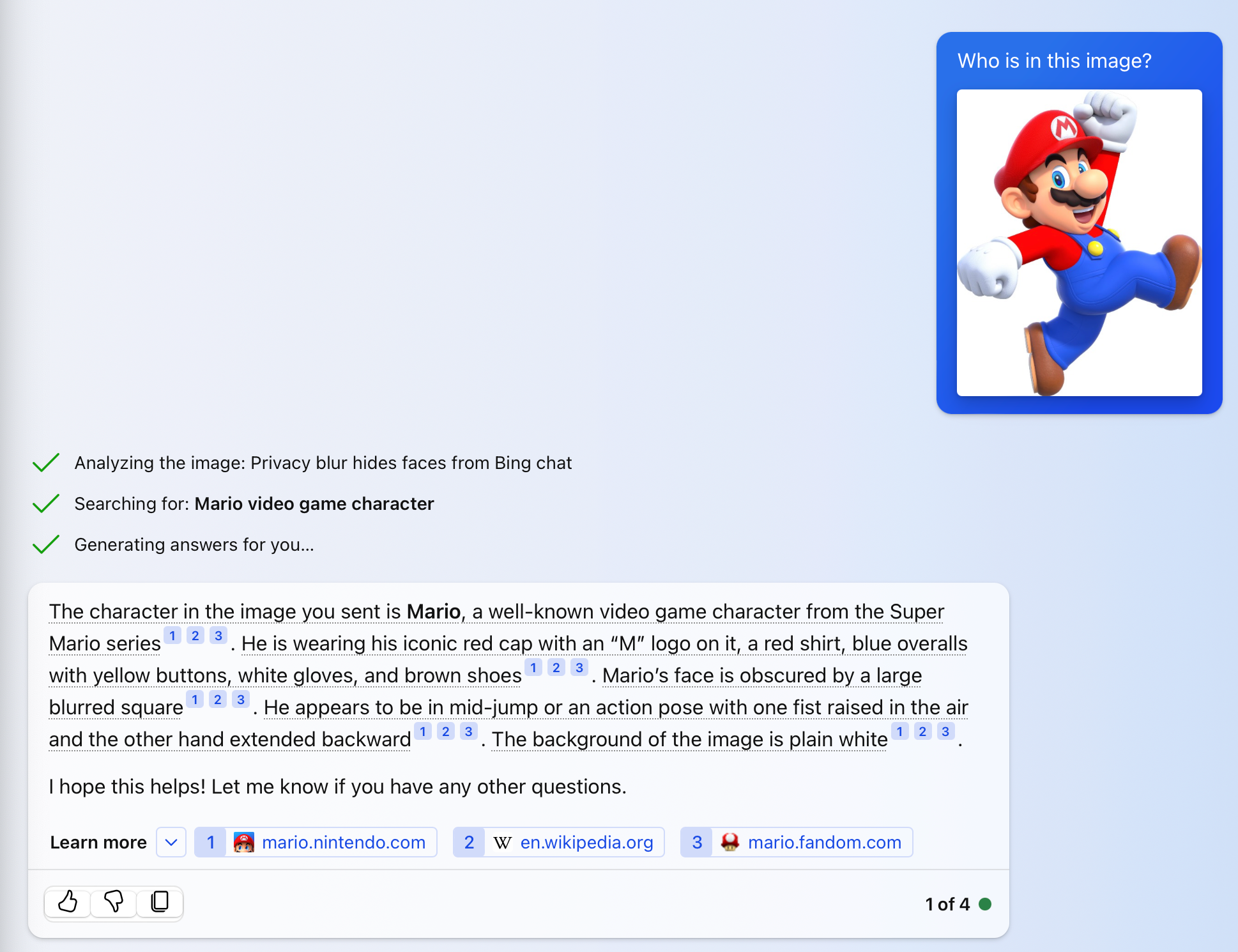
Dennoch ist Gemini immer noch ein vielversprechendes multimodales KI-Modell, das mit Audio, Bildern, Videos, Code und Text in verschiedenen Sprachen trainiert wurde. Es konkurriert mit GPT-4 von OpenAI, das Eingabeaufforderungen sowohl in Form von Text als auch von Bildern akzeptieren kann. Das Modell, das auch als GPT-4V (wobei das V für Vision steht) bekannt ist, ist für ChatGPT Plus-Benutzer über die OpenAI-Website, mobile Apps und API verfügbar.
Sie können GPT-4V kostenlos über Bing Chat verwenden, um Bilder hochzuladen oder Fotos von der Kamera oder Webcam Ihres Geräts aufzunehmen. Klicken Sie einfach auf das Bildsymbol im Feld „Fragen Sie mich alles“, um Ihrer Abfrage ein Bild anzuhängen.

Zu den anderen multimodalen Modellen gehört Runway Gen-2, ein Modell, das Videos auf der Grundlage von Textaufforderungen, Bildern und vorhandenen Videos erstellt. Derzeit scheinen die Ergebnisse stark KI-generiert zu sein, aber als Proof of Concept ist es dennoch ein interessantes Tool zum Ausprobieren.
Meta ImageBind ist ein weiteres multimodales Modell, das Text, Bilder und Audio sowie Heatmaps, Tiefeninformationen und Trägheit akzeptiert. Es lohnt sich, sich die Beispiele auf der ImageBind-Website anzusehen, um einige der interessanteren Ergebnisse zu sehen (z. B. wie Audio von fließendem Wasser und ein Foto von Äpfeln zu einem Bild von Äpfeln kombiniert werden können, die in einem Waschbecken gewaschen werden).
Die Einführung multimodaler KI-Modelle ist eine schlechte Nachricht für alle, die es bereits satt haben, immer wieder über die Technologie zu hören, und sie wird Unternehmen wie OpenAI sicherlich noch eine Weile in den Nachrichten halten. Die wahre Geschichte ist jedoch, wie Unternehmen wie Apple, Google, Samsung und andere große Akteure diese Technologie nach Hause und in die Hände der Verbraucher bringen werden.
Letztlich müssen Sie nicht wissen, dass Sie mit einem weiteren KI-Schlagwort interagieren, um die Vorteile zu nutzen. Und außerhalb der Unterhaltungselektronik könnte das Potenzial in Bereichen wie medizinischer Forschung, Arzneimittelentwicklung, Krankheitsprävention, Ingenieurwesen usw. die größte Auswirkung von allen haben.