

For the training of artificial neural networks, Tesla is currently still using accelerators from Nvidia. With the Dojo and the specially developed “D1” processors, Tesla is currently building its own supercomputer, which is supposed to deliver more performance with less consumption and less space. Dojo should achieve over 1 ExaFLOPS.
After the Full Self-Driving Computer (FSD) in the car, specially developed hardware is also in the Tesla data center. Nvidia is losing out in both areas, because in the long term the ampere accelerators are to be replaced by their own Tesla processors. For the training of artificial neural networks, Tesla currently relies on three clusters that work with a total of 11,544 Nvidia GPUs. A smaller cluster with 1,752 GPUs, 5 PB NVMe storage and InfiniBand adapters for networking the components is used for automated labeling, while two larger clusters, one with 4,032 GPUs and 8 PB NVMe storage and one with 5,760 GPUs and 12 PB NVMe storage, responsible for the training with a total of 9,792 GPUs.

D1 chip has 50 billion transistors
Tesla wants to get one with “Project Dojo” Build your own supercomputer architecture. The centerpiece is the specially developed D1 chip with 50 billion transistors from 7 nm production on an area of 645 mm². The processor provides a computing power of 362 TFLOPS based on BF16 and CFP8 (Configurable Floating Point 8) and 22.6 TFLOPS for FP32. Tesla specifies the TDP of the chip as 400 watts.
A D1 consists of 354 training nodes, each of which is home to a 64-bit superscalar CPU with four cores, which is specially designed for 8 × 8 matrix multiplication and the formats FP32, BFP16, CFP8, INT32, INT16 and INT8. Training nodes have a modular structure and, according to Tesla, can be linked in all directions via a “low latency switch fabric” with an on-chip bandwidth of 10 TB/s. Tesla spans an I/O ring with 576 lanes of 112 Gbit/s around the D1 for an off-chip bandwidth of 4 TB/s per side.
scalability without bottleneck
The advantage of the high bandwidth is the potential for scalability without bottlenecks. Tesla can, for example, link 1,500 D1 chips and thus 531,000 of the training nodes with one another without restrictions. “Dojo Interface Processors” are used on two sides of this D1 configuration, which Tesla did not explain further, but which have a fabric to the D1 on the one hand and PCIe Gen4 to the hosts in the data center on the other.
-
 D1-Chip (Image: Tesla)
D1-Chip (Image: Tesla)
Image 1 of 12
 D1-Chip
D1-Chip  Finished D1 chip
Finished D1 chip 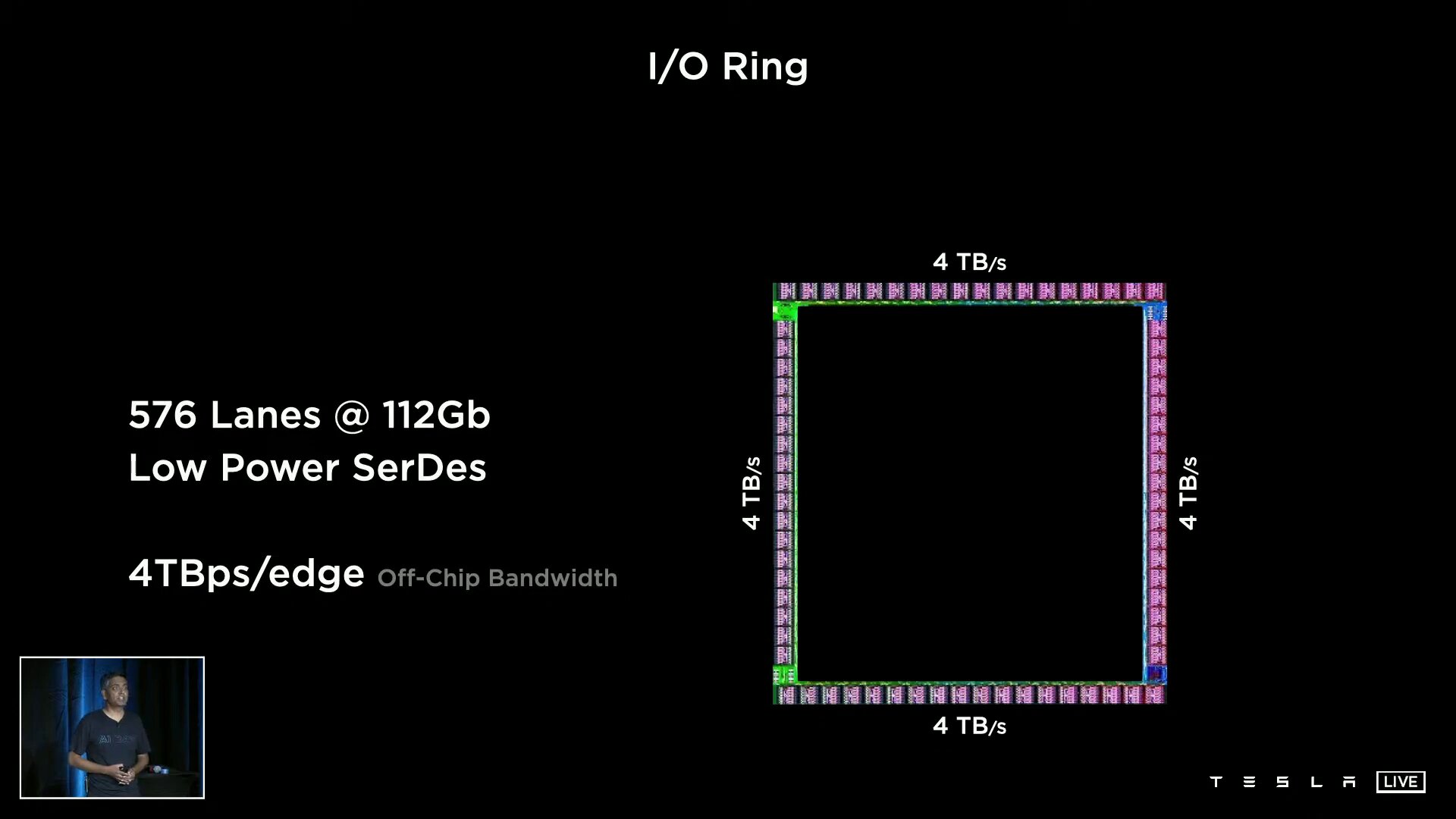
 10 TB/s on-chip bandwidth between nodes
10 TB/s on-chip bandwidth between nodes 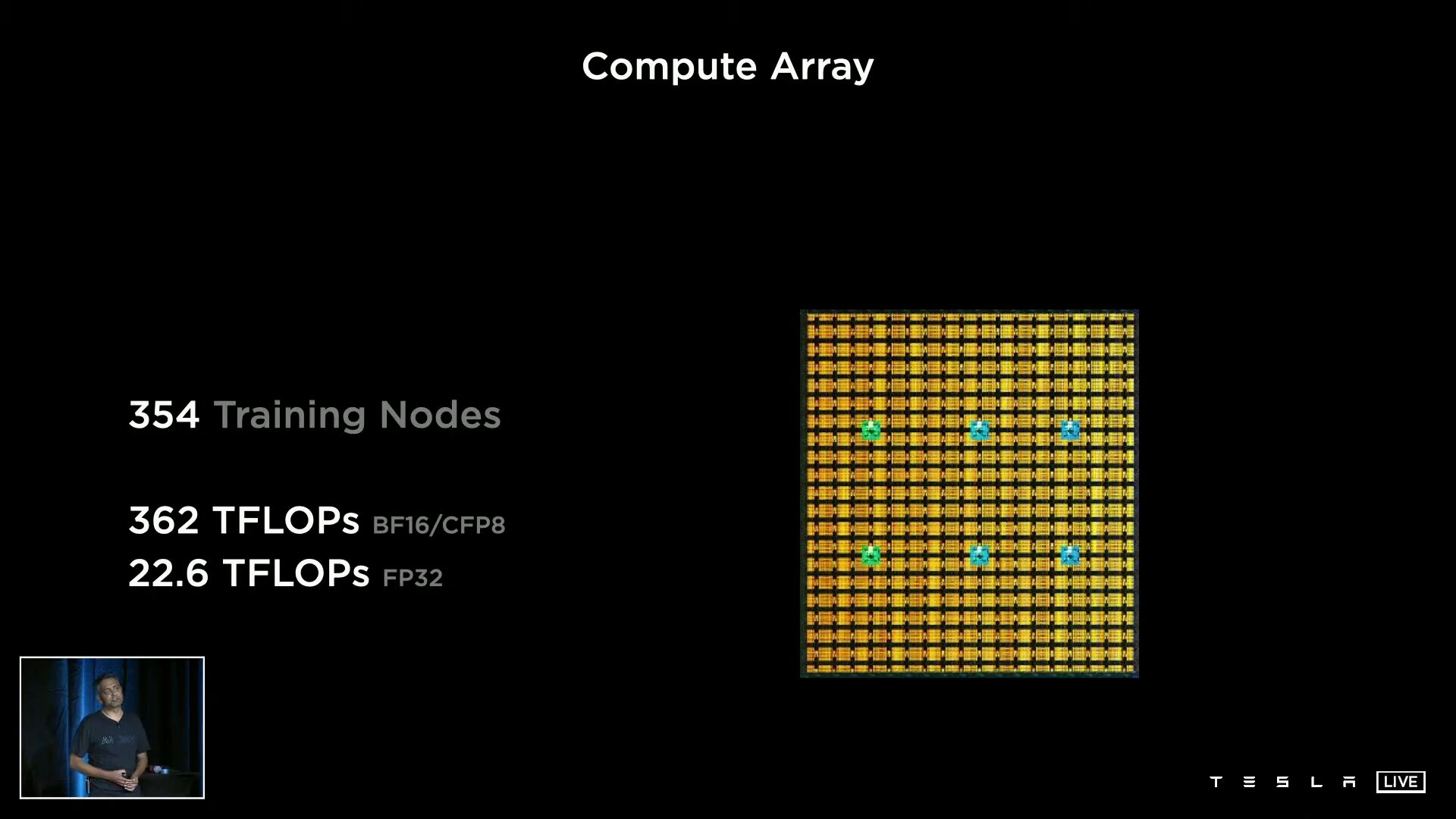 354 training nodes form a compute array
354 training nodes form a compute array  Structure of the CPU in the training node
Structure of the CPU in the training node  Reading of the CPU in the training node
Reading of the CPU in the training node 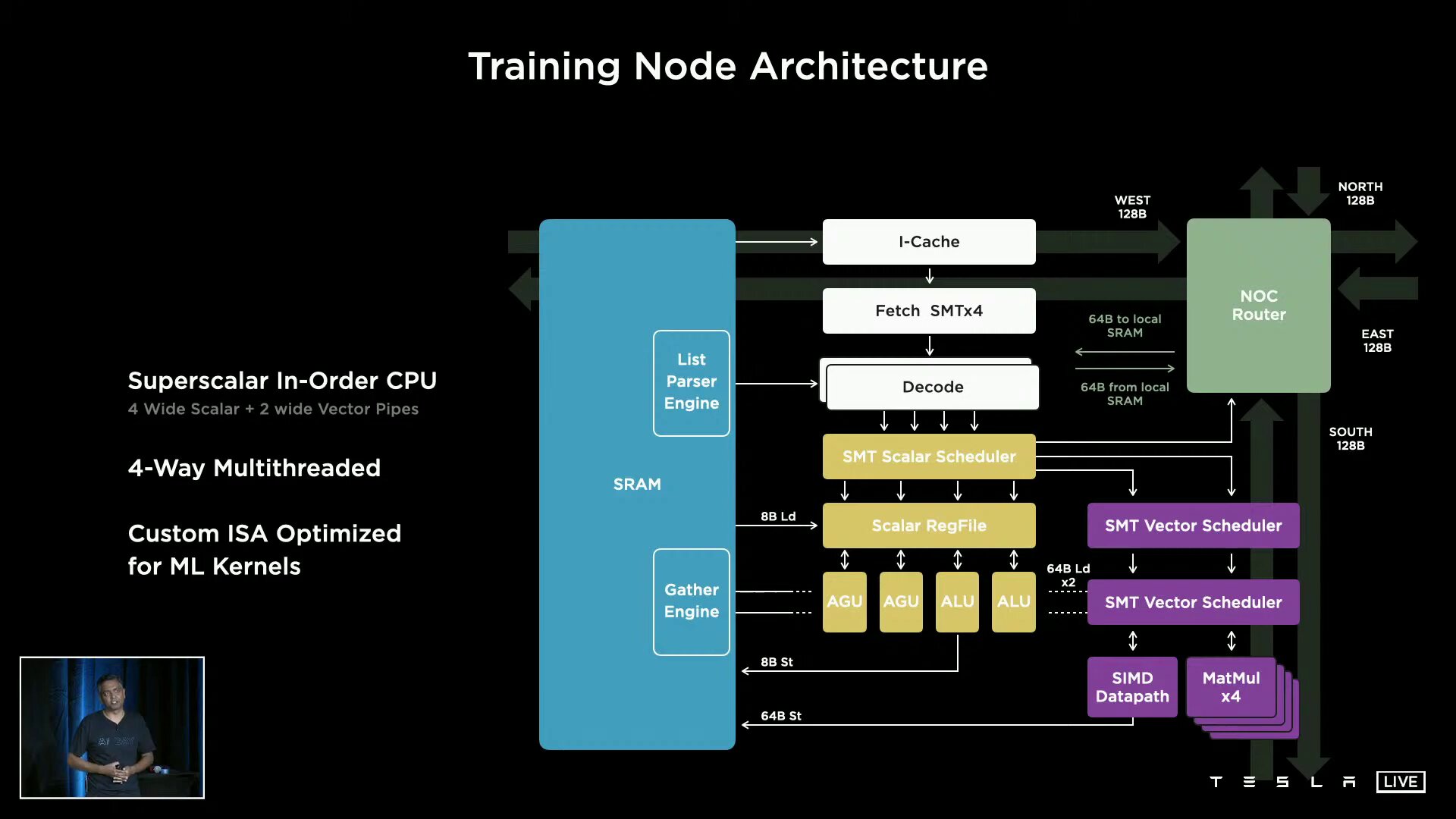 CPU of the training node in detail
CPU of the training node in detail 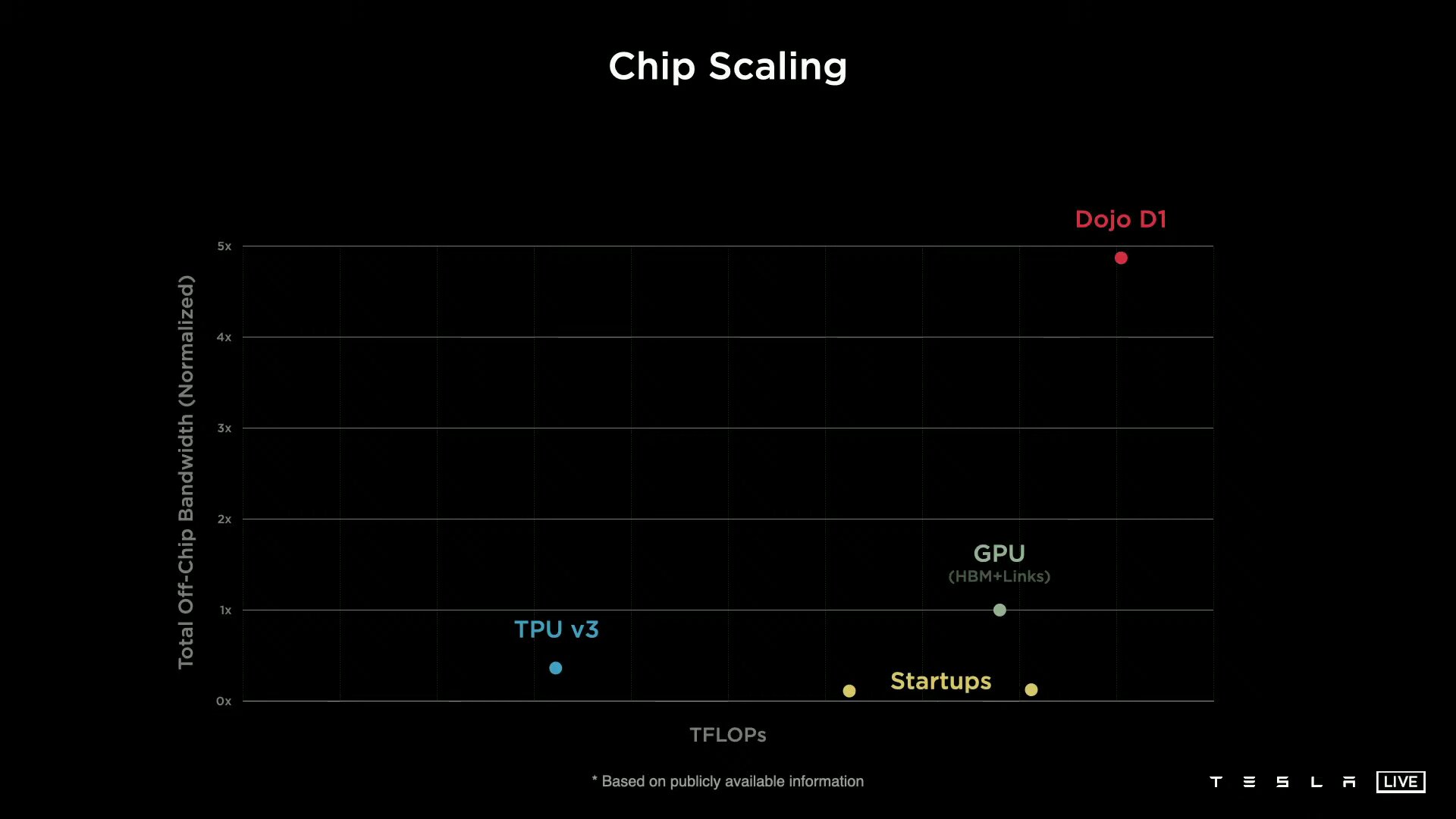
 Scalability to 1,500 D1 chips here
Scalability to 1,500 D1 chips here  Connectivity to the hosts in the data center
Connectivity to the hosts in the data center Training Tile with 28 liters volume and 9 PetaFLOPS
The total of 1,500 D1 chips are not directly linked to one another, but are combined in 5 × 5 units on a so-called training tile. Training Tile is then also the unit of measurement that Tesla uses for the entire Dojo supercomputer. 25 D1 dies are combined in a fan-out wafer process (presumably by TSMC) to form a training tile, which in turn has its own I/O ring with 9 TB/s in four directions and thus a bandwidth of 36 TB/s has. Tesla calls the Training Tile the largest “organic multi-chip module” currently in the industry. For the design, Tesla had to develop completely new tools that did not exist before. A training tile of 25 D1 delivers 9 PetaFLOPS BF16 or CFP8.
Cooling can dissipate 15 kilowatts
The energy is supplied vertically via a self-developed voltage regulator module that is applied directly to the fan-out wafer. In addition to the electronic structure with a 52 volt DC power supply, Tesla also independently developed the entire mechanical structure, including cooling. The latter must be able to dissipate waste heat of at least 25 × 400 watts only for D1, but including the other components, the solution is designed for 15 kilowatts. The finished module has a volume of less than a cubic foot, explains Tesla, which corresponds to around 28 liters. Last week Tesla put the first functional training Tile into operation at a clock rate of 2 GHz with limited cooling on a bench table for test purposes.
-
 Training Tiles (Image: Tesla)
Training Tiles (Image: Tesla)
Image 1 of 15
 Training Tiles
Training Tiles  25 D1 form a training Tile
25 D1 form a training Tile  25 D1 form a training tile
25 D1 form a training tile  25 D1 form a training tile
25 D1 form a training tile  25 D1 form a training Tile
25 D1 form a training Tile  I/O with 36 s for each training Tile
I/O with 36 s for each training Tile  Voltage regulator module on the wafer
Voltage regulator module on the wafer  Voltage regulator module on the wafer
Voltage regulator module on the wafer  Mechanical structure of the training tile
Mechanical structure of the training tile 
 Mechanical structure of the training tile
Mechanical structure of the training tile  Training tile reversed with cooling
Training tile reversed with cooling  Structure of the entire training tile
Structure of the entire training tile  Training tiles in test mode
Training tiles in test mode The ExaPOD contains 120 tiles for 1.1 ExaFLOPS of BF16 performance
Tesla, in turn, combines the training tiles in trays of 2 × 3 tiles and two of them in a cabinet, so that more than 100 PetaFLOPS are available per server cabinet with a bidirectional bandwidth of 12 TB/s. The end product is the finished Dojo supercomputer “ExaPOD” with 120 training tiles distributed over 10 cabinets and with a total of 3,000 D1 chips, which in turn have a total of 1,062,000 nodes. Tesla gives the total computing power with 1.1 ExaFLOPS for BF16/CFP8, so the computer does not win the worldwide exascale race, which is primarily aimed at FP64 applications. Nevertheless, upon completion it will stand for the world's fastest AI training supercomputer with four times the performance, 30 percent higher performance per watt and five times smaller footprint – at the same costs as before with Nvidia.
-
 3 × 2 Training Tiles × 2 Trays per Cabinet (Image: Tesla)
3 × 2 Training Tiles × 2 Trays per Cabinet (Image: Tesla)
Image 1 of 4
 3 × 2 Training Tiles × 2 Trays per Cabinet
3 × 2 Training Tiles × 2 Trays per Cabinet < figure>  120 training tiles connected to one another
120 training tiles connected to one another

 Advantages of the ExaPOD
Advantages of the ExaPOD